![]()
Free AWS-DevOps-Engineer-Professional braindumps download (AWS-DevOps-Engineer-Professional exam dumps Free Updated Jan 21, 2022)
AWS-DevOps-Engineer-Professional Dumps for Pass Guaranteed - Pass AWS-DevOps-Engineer-Professional Exam 2022
Target Audience & Peculiarities of AWS DevOps Engineer - Professional Test
This test is suitable for any DevOps engineer or developer who wants to learn how to work with AWS architecture and infrastructure solutions. Besides, it targets specialists who want to learn more about implementing and managing various delivery and control systems, ensure compliance validation, and configure AWS governance processes. This validation is also suitable for those who want to learn how to deploy and define monitoring systems with the help of AWS features. Passing the AWS DevOps Engineer – Professional exam will get you the namesake certificate. Amazon doesn’t have any obligatory prerequisites for eligible candidates. Still, it recommends that they should have previously worked with AWS environments for a minimum of 2 years. Also, they should have previously worked with high-level programming language systems and developed code concepts. Experience in building automated infrastructures is also a huge plus. Another recommendation would be that the examinees have previously administered operating systems and have a solid background in operating development processes and modern operations. As for the details of DOP-C01, its duration is 180 minutes. The candidates should obtain a minimum of 750 points if they want to get the certificate. Besides, they should pay the registration fee of $300. They can also enroll in the practice exam and pay an enrollment fee of $40. Finally, this test is available in the English language, as well as Simplified Chinese, Korean, and Japanese.
What Are Topics That AWS DOP-C01 Certification Exam Covers?
The AWS DOP-C01 exam is quite a difficult one as it takes candidates through six different topics, as follows:
- Automation Policies and Standards;
- Disaster Recovery, Fault Tolerance, High Availability.
- SDLC Automation;
- Configuration Management and Infrastructure as Code;
The first topic teaches candidates how to apply the correct concepts to ensure CI/CD pipeline automation. Also, they will become skilled in identifying source control strategies and implement them properly. Another ability developed in this domain would be related to testing integration and automation. Candidates should be ready to learn more about how to manage artifacts in a secure way and determine the right delivery and deployment strategies using AWS Services.
The second domain shows candidates the proper strategies to deploy services and applications based on business needs. Also, they will become pros in applying security concepts to ensure the automation of resource provisioning. Within this area, examinees will learn how to implement and deploy lifecycle hooks. Finally, they will understand more about the concepts necessary to manage different systems with the help of AWS configuration management services and tools.
The third chapter handles monitoring and logging principles. The specialists interested to learn more for their AWS DevOps Engineer – Professional exam should develop the abilities to apply concepts and services necessary for monitoring automation, event management, audit, logging, and monitoring of operating systems and AWS infrastructures. Also, they will learn how to develop and determine metadata strategies, metrics, aggregation, and logs storage.
Within the fourth section, candidates will understand more about the concepts related to logging, metrics, security, and monitoring of AWS services. Also, they will get to know more about determining cost optimization through automation. Another concept related to this chapter deals with governance strategies implementation.
Incident and Event Response is the fifth domain that is tested in the AWS DevOps Engineer – Professional certification. Those who are determined to take DOP-C01 will learn how to troubleshoot different issues and identify solutions to restore operations. They will become proficient in determining event management and alerting automation. The final subtopics included here are connected to automated healing implementation and event-driven automated actions set up.
Last but not least, high availability and disaster recovery are essential for success in your certification exam. It is important for candidates to know how to determine the differences between multi-AZ and multi-region concepts and how to implement them correctly. Also, applicants will learn how to implement fault tolerance, availability, and scalability AWS features. Another essential subtopic included in this chapter talks about choosing the right AWS services for different business needs. Candidates will as well learn how to evaluate the failure deployment and determine how to automate and design disaster recovery strategies.
Talking about the exam content, it covers six broad domains, which include the following:
- Response to Incidents and Events
This is the third largest area of the whole list of topics that covers 18% of the exam content. It is all about troubleshooting of the possible issues and determination of how to restore operations. It also includes the evaluation of your skills in applying different concepts that are required to implement automated healing or set up actions that are event-driven and automated. The knowledge of how to perform an automation process for alerting and event management is also essential.
- Infrastructure as Code and Configuration Management
This objective covers about 19% of the whole content. For this section, it is required that you understand all the needed concepts related to the deployment services that are based on deployment needs, infrastructure and app deployment models based on business needs, and the implementation of the lifecycle hooks on the deployment. This area also includes your knowledge of how to apply security concepts in the automation of resource provisioning and your ability to work with the concepts that are needed to manage systems with the use of AWS configuration management tools as well as services.
- Logging and Monitoring
You will face with about 15% of the questions from this domain during the exam. It evaluates your skills in applying various concepts that are required to automate event management and monitoring of an environment as well as monitor, log, and audit applications, infrastructures, and operating systems. Knowing how to set up the analysis of metrics and logs as well as their storage and aggregation is also important for the potential candidates. They have to also understand the implementation of tagging and other metadata strategies.
- Policies and Automation of Standards
This subject will cover only 10% of the exam content. This is the smallest amount of questions that you will encounter during the test. The subtopics of this domain include your understanding of cost optimization through automation, the ways to apply the concepts that are required to implement governance strategies, and your knowledge of which concepts are needed for the enforcement of the standards for security, testing, metrics, monitoring, and logging.
NEW QUESTION 102
You have the requirement to get a snapshot of the current configuration of the resources in your AWS Account. Which of the following services can be used for this purpose
- A. AWSConfig
- B. AWSIAM
- C. AWS CodeDeploy
- D. AWS Trusted Advisor
Answer: A
Explanation:
Explanation
The AWS Documentation mentions the following
With AWS Config, you can do the following:
* Evaluate your AWS resource configurations for desired settings.
* Get a snapshot of the current configurations of the supported resources that are associated with your AWS account.
* Retrieve configurations of one or more resources that exist in your account.
* Retrieve historical configurations of one or more resources.
* Receive a notification whenever a resource is created, modified, or deleted.
* View relationships between resources. For example, you might want to find all resources that use a particular security group. For more information on AWS Config, please visit the below URL:
* http://docs.aws.amazon.com/config/latest/developerguide/WhatlsConfig.html
NEW QUESTION 103
When thinking of AWS OpsWorks, which of the following is true?
- A. Instances have many stacks, stacks have many layers.
- B. Layers have many stacks, stacks have many instances.
- C. Layers have many instances, instances have many stacks.
- D. Stacks have many layers, layers have many instances.
Answer: D
Explanation:
The stack is the core AWS OpsWorks component. It is basically a container for AWS resources-- Amazon EC2 instances, Amazon RDS database instances, and so on--that have a common purpose and should be logically managed together. You define the stack's constituents by adding one or more layers. A layer represents a set of Amazon EC2 instances that serve a particular purpose, such as serving applications or hosting a database server. An instance represents a single computing resource, such as an Amazon EC2 instance.
http://docs.aws.amazon.com/opsworks/latest/userguide/welcome.html
NEW QUESTION 104
Which of the following is not a supported platform on Elastic Beanstalk?
- A. Go
- B. Nodejs
- C. PackerBuilder
- D. JavaSE
- E. Kubernetes
Answer: E
Explanation:
Explanation
Answer-C
Below is the list of supported platforms
*Packer Builder
*Single Container Docker
*Multicontainer Docker
*Preconfigured Docker
*Go
*Java SE
*Java with Tomcat
*NET on Windows Server with I IS
*Nodejs
*PHP
*Python
*Ruby
For
more information on the supported platforms please refer to the below link
http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/concepts.platforms. html
NEW QUESTION 105
You have a large number of web servers in an Auto Scaling group behind a load balancer. On an hourly basis, you want to filter and process the logs to collect data on unique visitors, and then put that data in a durable data store in order to run reports. Web servers in the Auto Scaling group are constantly launching and terminating based on your scaling policies, but you do not want to lose any of the log data from these servers during a stop/termination initiated by a user or by Auto Scaling.
What two approaches will meet these requirements?
Choose 2 answers
- A. On the web servers, create a scheduled task that executes a script to rotate and transmit the logs to Amazon Glacier.
Ensure that the operating system shutdown procedure triggers a logs transmission when the Amazon EC2 instance is stopped/terminated.
Use Amazon Data Pipeline to process the data in Amazon Glacier and run reports every hour. - B. Install an AWS Data Pipeline Logs Agent on every web server during the bootstrap process.
Create a log group object in AWS Data Pipeline, and define Metric Filters to move processed log data directly from the web servers to Amazon Redshift and run reports every hour. - C. On the web servers, create a scheduled task that executes a script to rotate and transmit the logs to an Amazon S3 bucket.
Ensure that the operating system shutdown procedure triggers a logs transmission when the Amazon EC2 instance is stopped/terminated.
Use AWS Data Pipeline to move log data from the Amazon S3 bucket to Amazon Redshift In order to process and run reports every hour. - D. Install an Amazon Cloudwatch Logs Agent on every web server during the bootstrap process.
Create a CloudWatch log group and define Metric Filters to create custom metrics that track unique visitors from the streaming web server logs.
Create a scheduled task on an Amazon EC2 instance that runs every hour to generate a new report based on the Cloudwatch custom metrics.
Answer: C,D
NEW QUESTION 106
Your organization has decided to implement a third-party configuration management tool that uses a master server from which nodes pull configuration.
You have built a custom base Amazon Machine Image that already has the third-party configuration management agent installed.
You want to use the same base AMI in Development, Test and Production environments, each of which has its own master server.
How should you configure your Amazon EC2 instances to register with the correct master server on launch?
- A. Create a tag for all instances that specifies their environment.
When launching instances, provide an Amazon EC2 UserData script that gets this tag by querying the MetaData Service and registers the agent with the master. - B. Create a script on your third-party configuration management master server that queries the Amazon EC2 API for new instances and registers them with it.
- C. Use Amazon CloudFormation to describe your environment.
Configure an input parameter for the master server hostname/address, and use this parameter within an Amazon EC2 UserData script that registers the agent with the master. - D. Use Amazon Simple Workflow Service to automate the process of registering new instances with your master server.
Use an Environment tag in Amazon EC2 to register instances with the correct master server.
Answer: C
NEW QUESTION 107
You run accounting software in the AWS cloud. This software needs to be online continuously during the day every day of the week, and has a very static requirement for compute resources. You also have other, unrelated batch jobs that need to run once per day at any time of your choosing. How should you minimize cost?
- A. Purchase a Medium Utilization Reserved Instance to run the accounting software. Turn it off after hours.
Run the batch jobs with the same instance class, so the Reserved Instance credits are also applied to the batch jobs. - B. Purchase a Full Utilization Reserved Instance to run the accounting software. Turn it off after hours. Run the batch jobs with the same instance class, so the Reserved Instance credits are also applied to the batch jobs.
- C. Purchase a Light Utilization Reserved Instance to run the accounting software. Turn it off after hours. Run the batch jobs with the same instance class, so the Reserved Instance credits are also applied to the batch jobs.
- D. Purchase a Heavy Utilization Reserved Instance to run the accounting software. Turn it off after hours. Run the batch jobs with the same instance class, so the Reserved Instance credits are also applied to the batch jobs.
Answer: D
Explanation:
Because the instance will always be online during the day, in a predictable manner, and there are a sequence of batch jobs to perform at any time, we should run the batch jobs when the account software is off. We can achieve Heavy Utilization by alternating these times, so we should purchase the reservation as such, as this represents the lowest cost. There is no such thing a "Full" level utilization purchases on EC2.
Reference:
https://d0.awsstatic.com/whitepapers/Cost_Optimization_with_AWS.pdf
NEW QUESTION 108
Using the AWS CLI, which command would you use to change the configuration settings for a CloudTrail trail?
- A. change-trail
- B. set-trail
- C. update-trail
- D. modify-trail
Answer: C
Explanation:
The update-trail command is used to change the configuration settings for a trail. You can only run update-trail command from the region in which the trail was created.
Reference:
http://docs.aws.amazon.com/awscloudtrail/latest/userguide/cloudtrail-create-and-update-a-trail- by-using-the-aws-cli.html
NEW QUESTION 109
A company has developed a static website hosted on an Amazon S3 bucket. The website is deployed using AWS CloudFormation. The CloudFormation template defines an S3 bucket and a custom resource that copies content into the bucket from a source location. The company has decided that it needs to move the website to a new location, so the existing CloudFormation stack must be deleted and re-created. However, CloudFormation reports that the stack could not be deleted cleanly.
What is the MOST likely cause and how can the DevOps Engineer mitigate this problem for this and future versions of the website?
- A. Deletion has failed because the S3 bucket has an active website configuration. Modify the CloudFormation template to remove the Website Configuration properly from the S3 bucket resource.
- B. Deletion has failed because the S3 bucket is not empty. Modify the custom resource's AWS Lambda function code to recursively empty the bucket when RequestType is Delete.
- C. Deletion has failed because the custom resource does not define a deletion policy. Add a DeletionPolicy property to the custom resource definition with a value of RemoveOnDeletion.
- D. Deletion has failed because the S3 bucket is not empty. Modify the S3 bucket resource in the CloudFormation template to add a DeletionPolicy property with a value of Empty.
Answer: B
NEW QUESTION 110
A media customer has several thousand amazon EC2 instances in an AWS account. The customer is using a Slack channel for team communications and important updates. A DevOps Engineer was told to send all AWS- scheduled EC2 maintenance notifications to the company Slack channel.
Which method should the Engineer use to implement this process in the LEAST amount of steps?
- A. Integrate EC2 events with Amazon CloudWatch monitoring. Based on the CloudWatch Alarm created, the alarm can invoke an AWS Lambda function to send EC2 maintenance notifications to the Slack channel.
- B. Integrate AWS Support with AWS CloudTrail. Based on the CloudTrail lookup event created, the event can invoke an AWS Lambda function to pass EC2 maintenance notifications to the Slack channel.
- C. Integrate AWS Trusted Advisor with AWS Config. Based on the AWS Config rules created, the AWS Config event can invoke an AWS Lambda function to send notifications to the Slack channel.
- D. Integrate AWS Personal Health Dashboard with Amazon CloudWatch Events. Based on the CloudWatch Events created, the event can invoke an AWS Lambda function to send notifications to the Slack channel.
Answer: A
Explanation:
Explanation/Reference: https://yabhinav.github.io/cloud/awslambda-slack-notifications/
NEW QUESTION 111
An n-tier application requires a table in an Amazon RDS MySQL DB instance to be dropped and repopulated at each deployment. This process can take several minutes and the web tier cannot come online until the process is complete. Currently, the web tier is configured in an Amazon EC2 Auto Scaling group, with instances being terminated and replaced at each deployment. The MySQL table is populated by running a SQL query through an AWS CodeBuild job.
What should be done to ensure that the web tier does not come online before the database is completely configured?
- A. Modify the launch configuration of the Auto Scaling group to pause user data execution for 600 seconds, allowing the table to be populated.
- B. Use AWS Step Functions to monitor and maintain the state of data population. Mark the database in service before continuing with the deployment.
- C. Use Amazon Aurora as a drop-in replacement for RDS MySQL. Use snapshots to populate the table with the correct data.
- D. Use an EC2 Auto Scaling lifecycle hook to pause the configuration of the web tier until the table is populated.
Answer: A
NEW QUESTION 112
You have been given a business requirement to retain log files for your application for 10 years. You need to
regularly retrieve the most recent logs for troubleshooting. Your logging system must be cost-effective, given
the large volume of logs. What technique should you use to meet these requirements?
- A. Store your logs on Amazon EBS, and use Amazon EBS snapshots to archive them.
- B. Store your log in Amazon CloudWatch Logs.
- C. Store your logs in Amazon Glacier.
- D. Store your logs in Amazon S3, and use lifecycle policies to archive to Amazon Glacier.
Answer: D
Explanation:
Explanation
Option A is invalid, because cloud watch will not store the logs indefinitely and secondly it won't be the cost
effective option.
Option B is invalid, because it won't server the purpose of regularly retrieve the most recent logs for
troubleshooting. You will need to pay more to retrieve the logs
faster from this storage.
Option D is invalid, because it is not an ideal or cost effective option.
You can define lifecycle configuration rules for objects that have a well-defined lifecycle. For example:
* if you are uploading periodic logs to your bucket, your application might need these logs for a week or a
month after creation, and after that you might want to delete them.
* Some documents are frequently accessed for a limited period of time. After that, these documents are
less frequently accessed. Over time, you might not need real-time access to these objects, but your
organization or regulations might require you to archive them for a longer period and then optionally
delete them later.
* You might also upload some types of data to Amazon S3 primarily for archival purposes, for example
digital media archives, financial and healthcare records, raw genomics sequence data, long-term
database backups, and data that must be retained for regulatory compliance.
For more information on Lifecycle management please refer to the below link:
* http://docs.aws.a
mazon.com/AmazonS3/latest/dev/object-lifecycle-mgmt.htm I
Note:
Option C is the cheapest option, but Cloud watch can store logs indefinetly or between 10 years and one day.
"Log Retention-By default, logs are kept indefinitely and never expire. You can adjust the retention policy
for each log group, keeping the indefinite retention, or
choosing a retention periods between 10 years and one day."
* https://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/WhatlsCloud WatchLogs.html
NEW QUESTION 113
A DevOps engineer needs to back up sensitive Amazon S3 objects that are stored within an S3 bucket with a private bucket policy using S3 cross-Region replication functionality. The objects need to be copied to a target bucket In a different AWS Region and account.
Which combination of actions should be performed to enable this replication? (Select THREE.)
- A. Create a replication 1AM role in the target account.
- B. Create a replication rule in the source bucket to enable the replication.
- C. Create a replication rule in the target bucket to enable the replication
- D. Add statements to the source bucket policy allowing the replication 1AM role to replicate objects
- E. Create a replication 1AM role in the source account.
- F. Add statements to the target bucket policy allowing the replication 1AM role to replicate objects.
Answer: A,B
NEW QUESTION 114
You have a large number of web servers in an Auto Scalinggroup behind a load balancer. On an hourly basis, you want to filter and process the logs to collect data on unique visitors, and then put that data in a durable data store in order to run reports. Web servers in the Auto Scalinggroup are constantly launching and terminating based on your scaling policies, but you do not want to lose any of the log data from these servers during a stop/termination initiated by a user or by Auto Scaling. What two approaches will meet these requirements? Choose two answers from the optionsgiven below.
- A. On the web servers, create a scheduled task that executes a script to rotate and transmit the logs to an Amazon S3 bucket. Ensure that the operating system shutdown procedure triggers a logs transmission when the Amazon EC2 instance is stopped/terminated. Use AWS Data Pipeline to move log data from the Amazon S3 bucket to Amazon Redshift In order to process and run reports every hour.
- B. On the web servers, create a scheduled task that executes a script to rotate and transmit the logs to Amazon Glacier. Ensure that the operating system shutdown procedure triggers a logs transmission when the Amazon EC2 instance is stopped/terminated. Use Amazon Data Pipeline to process the data in Amazon Glacier and run reports every hour.
- C. Install an AWS Data Pipeline Logs Agent on every web server during the bootstrap process. Create a log group object in AWS Data Pipeline, and define Metric Filters to move processed log data directly from the web servers to Amazon Redshift and run reports every hour.
- D. Install an Amazon Cloudwatch Logs Agent on every web server during the bootstrap process. Create a CloudWatch log group and define Metric Filters to create custom metrics that track unique visitors from the streaming web server logs.
Create a scheduled task on an Amazon EC2 instance that runs every hour to generate a new report based on the Cloudwatch custom metrics. ^/
Answer: A,D
Explanation:
Explanation
You can use the Cloud Watch Logs agent installer on an existing CC2 instance to install and configure the Cloud Watch Logs agent.
For more information, please visit the below link:
* http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/Qu
ickStartCC2lnstance.html
You can publish your own metrics to Cloud Watch using the AWS CLI or an API. For more information, please visit the below link:
* http://docs.aws.amazon.com/AmazonCloudWatch/latest/monitoring/publ
ishingMetrics.html
Amazon Redshift is a fast, fully managed data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing Business Intelligence (Bl) tools. It allows you to run complex analytic queries against petabytes of structured data, using sophisticated query optimization, columnar storage on high-performance local disks, and massively parallel query execution. Most results come back in seconds.
For more information on copying data from S3 to redshift, please refer to the below link:
* http://docs.aws.amazon.com/datapipeline/latest/DeveloperGuide/dp-copydata- redshift html
NEW QUESTION 115
A company has a hybrid architecture solution in which some legacy systems remain on-premises, while a specific cluster of servers is moved to AWS. The company cannot reconfigure the legacy systems, so the cluster nodes must have a fixed hostname and local IP address for each server that is part of the cluster. The DevOps Engineer must automate the configuration for a six-node cluster with high availability across three Availability Zones (AZs), placing two elastic network interfaces in a specific subnet for each AZ. Each node's hostname and local IP address should remain the same between reboots or instance failures.
Which solution involves the LEAST amount of effort to automate this task?
- A. Create an Amazon DynamoDB table with the list of hostnames, subnets, and elastic network interfaces to be used. Create a single AWS CloudFormation template to manage an Auto Scaling group with a minimum size of 6 and a maximum size of 6. Create a programmatic solution that is installed in each instance that will lock/release the assignment of each hostname and local IP address, depending on the subnet in which a new instance will be launched.
- B. Create a reusable AWS CLI script to launch each instance individually, which will name the instance, place it in a specific AZ, and attach a specific elastic network interface. Monitor the instances, and in the event of failure, replace the missing instance manually by running the script again.
- C. Create a reusable AWS CloudFormation template to manage an Amazon EC2 Auto Scaling group with a minimum size of 1 and a maximum size of 1. Give the hostname, elastic network interface, and AZ as stack parameters. Use those parameters to set up an EC2 instance with EC2 Auto Scaling and a user data script to attach to the specific elastic network interface. Use CloudFormation nested stacks to nest the template six times for a total of six nodes needed for the cluster, and deploy using the master template.
- D. Create an AWS Elastic Beanstalk application and a specific environment for each server of the cluster. For each environment, give the hostname, elastic network interface, and AZ as input parameters. Use the local health agent to name the instance and attach a specific elastic network interface based on the current environment.
Answer: C
NEW QUESTION 116
Your company develops a variety of web applications using many platforms and programming languages with different application dependencies. Each application must be developed and deployed quickly and be highly available to satisfy your business requirements. Which of the following methods should you use to deploy these applications rapidly?
- A. Store each application's code in a Git repository, develop custom package repository managers for each application's dependencies, and deploy to AWS OpsWorks in multiple Availability Zones.
- B. Use the AWS CloudFormation Docker import service to build and deploy the applications with high availability in multiple Availability Zones.
C- Develop each application's code in DynamoDB, and then use hooks to deploy it to Elastic Beanstalk environments with Auto Scaling and Elastic Load Balancing. - C. Develop the applications in Docker containers, and then deploy them to Elastic Beanstalk environments with Auto Scaling and Elastic Load Balancing.
Answer: C
Explanation:
Explanation
Elastic Beanstalk supports the deployment of web applications from Docker containers. With Docker containers, you can define your own runtime environment. You can choose your own platform, programming language, and any application dependencies (such as package managers or tools), that aren't supported by other platforms. Docker containers are self-contained and include all the configuration information and software your web application requires to run.
By using Docker with Elastic Beanstalk, you have an infrastructure that automatically handles the details of capacity provisioning, load balancing, scaling, and application health monitoring.
For more information on Dockers and Elastic beanstalk please refer to the below link:
* http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/create_deploy_docker.html
NEW QUESTION 117
A DevOps Engineer is leading the implementation for automating patching of Windows-based workstations in a hybrid cloud environment by using AWS Systems Manager (SSM).
What steps should the Engineer follow to set up Systems Manager to automate patching in this environment?
(Select TWO.)
- A. Run AWS Config to create a list of instances that are unpatched and not compliant. Create an instance scheduler job, and through an AWS Lambda function, perform the instance patching to bring them up to compliance.
- B. Create an IAM service role for Systems Manager so that the ssm amazonaws.com service can execute the AssumeRole operation. Register the role to enable the creation of a service token. Perform managed-instance activation with the newly created service role.
- C. Create multiple IAM service roles for Systems Manager so that the ssm amazonaws.com service can execute the AssumeRole operation on every instance. Register the role on a per-resource level to enable the creation of a service token. Perform managed-instance activation with the newly created service role attached to each managed instance.
- D. Using previously obtained activation codes and activation IDs, download and install the SSM Agent on the hybrid servers, and register the servers or virtual machines on the Systems Manager service. Hybrid instances will show with an "mi-" prefix in the SSM console.
- E. Using previously obtained activation codes and activation IDs, download and install the SSM Agent on the hybrid servers, and register the servers or virtual machines on the Systems Manager service. Hybrid instances will show with an "i-" prefix in the SSM console as if they were provisioned as a regular Amazon EC2 instance.
Answer: A,B
NEW QUESTION 118
Which of the following will you need to consider so you can set up a solution that incorporates single sign-on from your corporate AD or LDAP directory and restricts access for each user to a designated user folder in a bucket? Choose 3 Answers from the options below
- A. Setting up a matching 1AM user for every user in your corporate directory that needs access to a folder in the bucket
- B. Tagging each folder in the bucket
- C. Configuring 1AM role
- D. Setting up a federation proxy or identity provider
- E. Using AWS Security Token Service to generate temporary tokens
Answer: C,D,E
Explanation:
Explanation
The below diagram showcases how authentication is carried out when having an identity broker. This is an example of a SAML connection, but the same concept holds true for getting access to an AWS resource.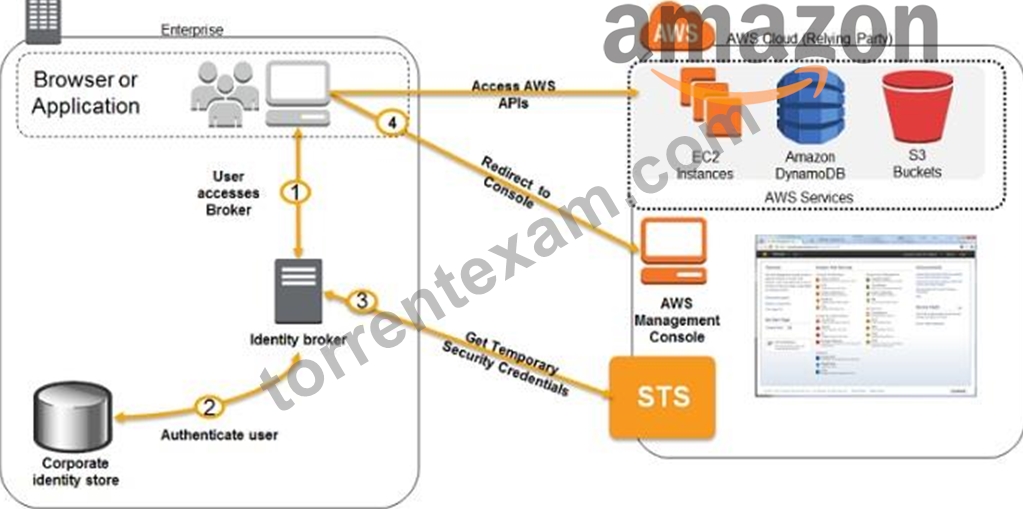
For more information on federated access, please visit the below link:
* http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_common-scenarios_federated-users.html
* https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create_for-idp_samI.html?icmpid=docs_iam_console
* https://aws.amazon.com/blogs/security/writing-iam-policies-grant-access-to-user-specific-folders-in-an-amazon-s3-bucket/
NEW QUESTION 119
A DevOps engineer used an AWS CloudFormation custom resource to set up AD Connector. The AWS Lambda function executed and created AD Connector, but CloudFormation is not transitioning from CREATE_IN_PROGRESS to CREATE.COMPLETE.
Which action should the engineer take to resolve this issue?
- A. Ensure the Lambda function code returns a response to the pre-signed URL.
- B. Ensure the Lambda function IAM role has cloudformation:UpdateStack permissions for the stack ARN.
- C. Ensure the Lambda function code has exiled successfully.
- D. Ensure the Lambda function IAM role has ds:ConnectDirectory permissions for the AWS account.
Answer: A
NEW QUESTION 120
Your company has developed a web application and is hosting it in an Amazon S3 bucket configured for static website hosting.
The application is using the AWS SDK for JavaScript in the browser to access data stored in an Amazon DynamoDB table.
How can you ensure that API keys for access to your data in DynamoDB are kept secure?
- A. Create an Amazon S3 role in IAM with access to the specific DynamoDB tables, and assign it to the bucket hosting your website.
- B. Store AWS keys in global variables within your application and configure the application to use these credentials when making requests.
- C. Configure a web identity federation role within IAM to enable access to the correct DynamoDB resources and retrieve temporary credentials.
- D. Configure S3 bucket tags with your AWS access keys for your bucket hosing your website so that the application can query them for access.
Answer: C
NEW QUESTION 121
A Development team is adding a new country to an e-commerce application. This addition requires that new application features be added to the shipping component of the application. The team has not decided if all new features should be added, as some will take approximately six weeks to build. While the final decision on the shipping component features is being made, other team members are continuing to work on other features of the application. Based on this situation, how should the application feature deployments be managed?
- A. Add the code updates as commits to a feature branch. Merge the commits to a release branch as features are ready.
- B. Create a new repository named "new-country". Commit all the code changes to the new repository.
- C. Add the code updates as commits to the release branch. The team can delay the deployment until all features are ready.
- D. Add the code updates as a single commit when a feature is ready. Tag this commit with "new-country."
Answer: A
NEW QUESTION 122
You have a fleet of Elastic Compute Cloud (EC2) instances in an Auto Scaling group.
All of these instances are running Microsoft Windows Server 2012 backed by Amazon Elastic Block Store (EBS).
These instances were launched through AWS CloudFormation.
You have determined that your instances are underutilized, and in order to save some money, have decided to modify the instance type of the fleet.
In which of the following ways can you achieve the desired result during a scheduled maintenance window? Choose 2 answers
- A. Take snapshots of the running instances, and launch new instances based on those snapshots.
- B. Change the instance type in the AWS CloudFormation template that was used to create the Amazon EC2 instances, and then update the stack.
- C. Use the AWS Command Line Interface (CLI) to modify the instance type of each running instance.
- D. Identify the new instance type in the user data and restart the running instances one at a time.
- E. Create a new Auto Scaling launch configuration specifying the new instance type, associate it to the existing Auto Scaling group, and terminate the running instances.
Answer: B,E
NEW QUESTION 123
......
Verified AWS-DevOps-Engineer-Professional dumps Q&As - Pass Guarantee Exam Dumps Test Engine: https://dumpscertify.torrentexam.com/AWS-DevOps-Engineer-Professional-exam-latest-torrent.html