![]()
Guaranteed High Marks with Updated & Real CT-AI Dumps pdf Free Updates
PASS RATE ISTQB AI Testing CT-AI Certified Exam DUMP
ISTQB CT-AI Exam Syllabus Topics:
| Topic | Details |
|---|---|
| Topic 1 |
|
| Topic 2 |
|
| Topic 3 |
|
| Topic 4 |
|
| Topic 5 |
|
| Topic 6 |
|
| Topic 7 |
|
| Topic 8 |
|
NEW QUESTION # 29
Which of the following descriptions of quality aspects of a data set is correct?
Choose ONE option (1 out of 4)
- A. The quality aspect "Data not preprocessed" describes the fact that the collected data was recorded incorrectly.
- B. The quality aspect "Incomplete data" describes the fact that data is missing, e.g., for a certain time interval.
- C. The quality aspect "Irrelevant data" describes the fact that irrelevant data does not affect the ML model.
- D. The quality aspect "Unbalanced data" describes the fact that the data used should be as up-to-date as possible.
Answer: B
Explanation:
The ISTQB CT-AI syllabus describes severaldata quality aspectsthat affect ML performance. In Section2.2
- Data Preparation, it explains that datasets may suffer from issues such asincomplete data,irrelevant data, incorrect data,unbalanced data, or data lacking preprocessing. "Incomplete data" means thatportions of the required data are missing, often because some time periods, records, or sources were not captured. This aligns exactly with Option A, which correctly identifies missing intervals as incomplete data.
Option B is incorrect: "data not preprocessed" refers to data that has not undergone normalization, cleaning, or transformation-not data recorded incorrectly. Option C is wrong because irrelevant datadoesnegatively affect ML models by introducing noise and unnecessary features. The syllabus explicitly states that including irrelevant features can degrade model learning. Option D is incorrect: "unbalanced data" relates to disproportionate class distribution, not recency or freshness of data.
Thus, OptionAis the only statement that correctly matches the syllabus definition of this data quality aspect.
NEW QUESTION # 30
You are testing an autonomous vehicle which uses AI to determine proper driving actions and responses. You have evaluated the parameters and combinations to be tested and have determined that there are too many to test in the time allowed. It has been suggested that you use pairwise testing to limit the parameters. Given the complexity of the software under test, what is likely the outcome from using pairwise testing?
- A. All high priority defects will be identified using this method
- B. While the number of tests needed can be reduced, there may still be a large enough set of tests that automation will be required to execute all of them
- C. Pairwise cannot be applied to this problem because there is AI involved and the evolving values may result in unexpected results that cannot be verified
- D. The number of parameters to test can be reduced to less than a dozen
Answer: B
Explanation:
The syllabus states that while pairwise testing is effective at finding defects by reducing the number of test cases needed, the resulting test suite can still be extensive and require automation:
"Even the use of pairwise testing can result in extensive test suites... automation and virtual test environments often become necessary to allow the required tests to be run." (Reference: ISTQB CT-AI Syllabus v1.0, Section 9.2, Page 67 of 99)
NEW QUESTION # 31
Which of the following characteristics of AI-based systems make it more difficult to ensure they are safe?
- A. Sustainability
- B. Simplicity
- C. Non-determinism
- D. Robustness
Answer: C
Explanation:
AI-based systems oftenexhibit non-deterministic behavior, meaning theydo not always produce the same output for the same input. This makesensuring safety more difficult, as the system's behavior can change based on new data, environmental factors, or updates.
* Why Non-determinism Affects Safety:
* In traditional software, the same input always produces the same output.
* In AI systems, outputsvary probabilisticallydepending on learned patterns and weights.
* This unpredictability makes itharder to verify correctness, reliability, and safety, especially in critical domains likeautonomous vehicles, medical AI, and industrial automation.
* A (Simplicity):AI-based systems are typicallycomplex, not simple, which contributes to safety challenges.
* B (Sustainability):While sustainability is an important AI consideration, it doesnot directly affect safety.
* D (Robustness):Lack of robustnesscan make AI systems unsafe, butnon-determinism is the primary issuethat complicates safety verification.
* ISTQB CT-AI Syllabus (Section 2.8: Safety and AI)
* "The characteristics of AI-based systems that make it more difficult to ensure they are safe include: complexity, non-determinism, probabilistic nature, self-learning, lack of transparency, interpretability and explainability, lack of robustness".
Why Other Options Are Incorrect:Supporting References from ISTQB Certified Tester AI Testing Study Guide:Conclusion:Sincenon-determinism makes AI behavior unpredictable, complicating safety assurance, thecorrect answer is C.
NEW QUESTION # 32
A company is using a spam filter to attempt to identify which emails should be marked as spam. Detection rules are created by the filter that causes a message to be classified as spam. An attacker wishes to have all messages internal to the company be classified as spam. So, the attacker sends messages with obvious red flags in the body of the email and modifies the "from" portion of the email to make it appear that the emails have been sent by company members. The testers plan to use exploratory data analysis (EDA) to detect the attack and use this information to prevent future adversarial attacks.
How could EDA be used to detect this attack?
- A. EDA can restrict how many inputs can be provided by unique users
- B. EDA can detect and remove the false emails
- C. EDA cannot be used to detect the attack
- D. EDA can help detect the outlier emails from the real emails
Answer: D
Explanation:
The syllabus explains that EDA can be used to analyze data to identify outliers and unusual patterns, which can indicate adversarial attacks like data poisoning:
"Testing to detect data poisoning is possible using EDA, as poisoned data may show up as outliers." (Reference: ISTQB CT-AI Syllabus v1.0, Section 9.1.2, page 67 of 99)
NEW QUESTION # 33
A system was developed for screening the X-rays of patients for potential malignancy detection (skin cancer).
A workflow system has been developed to screen multiple cancers by using several individually trained ML models chained together in the workflow.
Testing the pipeline could involve multiple kind of tests (I - III):
I.Pairwise testing of combinations
II.Testing each individual model for accuracy
III.A/B testing of different sequences of models
Which ONE of the following options contains the kinds of tests that would be MOST APPROPRIATE to include in the strategy for optimal detection?
SELECT ONE OPTION
- A. Only III
- B. Only II
- C. I and III
- D. I and II
Answer: D
Explanation:
The question asks which combination of tests would be most appropriate to include in the strategy for optimal detection in a workflow system using multiple ML models.
* Pairwise testing of combinations (I): This method is useful for testing interactions between different components in the workflow to ensure they work well together, identifying potential issues in the integration.
* Testing each individual model for accuracy (II): Ensuring that each model in the workflow performs accurately on its own is crucial before integrating them into a combined workflow.
* A/B testing of different sequences of models (III): This involves comparing different sequences to determine which configuration yields the best results. While useful, it might not be as fundamental as pairwise and individual accuracy testing in the initial stages.
:
ISTQB CT-AI Syllabus Section 9.2 on Pairwise Testing and Section 9.3 on Testing ML Models emphasize the importance of testing interactions and individual model accuracy in complex ML workflows.
NEW QUESTION # 34
Which of the following is an example of an input change where it would be expected that the AI system should be able to adapt?
- A. It has been trained to analyze customer buying trend data and is given information on supplier cost data.
- B. It has been trained to recognize human faces at a particular resolution and it is given a human face image captured with a higher resolution.
- C. It has been trained to recognize cats and is given an image of a dog.
- D. It has been trained to analyze mathematical models and is given a set of landscape pictures to classify.
Answer: B
Explanation:
AI systems, particularly machine learning models, need to exhibit adaptability and flexibility to handle slight variations in input data without requiring retraining. The ISTQB CT-AI syllabus outlines adaptability as a crucial feature of AI systems, especially when the system is exposed to variations in its operational environment.
* Option A:"It has been trained to recognize cats and is given an image of a dog."
* This scenario introduces an entirely new class (dogs), which is outside the AI system's expected scope. If the AI was only trained to recognize cats, it would not be expected to recognize dogs correctly without retraining. This does not demonstrate adaptability as expected from an AI system.
* Option B:"It has been trained to recognize human faces at a particular resolution and it is given a human face image captured with a higher resolution."
* This is an example of an AI system encountering a variation of its training data rather than entirely new data. Most AI-based image processing models can adapt to different resolutions by applying downsampling or other pre-processing techniques. Since the data remains within the domain of human faces, the model should be able to process the higher-resolution image without significant issues.
* Option C:"It has been trained to analyze mathematical models and is given a set of landscape pictures to classify."
* This represents a complete shift in the data type from structured numerical data to unstructured image data. The AI system is unlikely to adapt effectively, as it has not been trained on image classification tasks.
* Option D:"It has been trained to analyze customer buying trend data and is given information on supplier cost data."
* This introduces a significant domain shift. Customer buying trends focus on consumer behavior, while supplier cost data relates to pricing structures and logistics. The AI system would likely require retraining to process the new data meaningfully.
* Adaptability Requirements:The syllabus discusses that AI-based systems must be able to adapt to changes in their operational environment and constraints, including minor variations in input quality (such as resolution changes).
* Autonomous Learning & Evolution:AI systems are expected to improve and handle evolving inputs based on prior experience.
* Challenges in Testing Self-Learning Systems:AI systems should be tested to ensure they function correctly when encountering new but related data, such as different resolutions of the same object.
Analysis of the Answer Options:ISTQB CT-AI Syllabus References:Thus,option Bis the best choice as it aligns with the adaptability characteristics expected from AI-based systems.
NEW QUESTION # 35
How can a tester check the system for bias as part of a review of data sources, acquisition, and preprocessing?
Choose ONE option (1 out of 4)
- A. During the review of the preprocessing, the auditor can uncover whether the data has been influenced in a way that could lead to sample distortions.
- B. It may use the LIME method as part of its data collection review to detect inappropriate bias.
- C. As part of the review of preprocessing, it can reveal whether the data has been influenced in a way that could lead to algorithmic bias.
- D. During the review, it can uncover algorithmic bias by analysing the procedures used to obtain the training data.
Answer: A
Explanation:
Bias detection at thedata levelis performed by reviewingdata acquisition and preprocessing steps, as explained in Section2.3 - Data Quality and Biasof the ISTQB CT-AI syllabus. Sample bias arises when data is distorted or when preprocessing introduces unintended shifts-for example, by filtering, normalization, or labeling steps that disproportionately affect subsets of the data. OptionBcorrectly reflects this: reviewers can identify whether preprocessing steps have altered the dataset in a way that introducessample distortions. This aligns perfectly with syllabus guidance on reviewing data pipelines for bias sources.
Option A is incorrect because algorithmic bias originates from themodel, not data collection procedures.
Option C is incorrect because LIME is anexplainabilitymethod applied post-model, not in data reviews.
Option D incorrectly states "algorithmic bias," but preprocessing affectssample bias, not algorithmic bias.
Thus, OptionBcorrectly matches the syllabus' definition of how bias can be detected during data-related reviews.
NEW QUESTION # 36
A company producing consumable goods wants to identify groups of people with similar tastes for the purpose of targeting different products for each group. You have to choose and apply an appropriate ML type for this problem.
Which ONE of the following options represents the BEST possible solution for this above-mentioned task?
SELECT ONE OPTION
- A. Association
- B. Classification
- C. Regression
- D. Clustering
Answer: D
Explanation:
A . Regression
Regression is used to predict a continuous value and is not suitable for grouping people based on similar tastes.
B . Association
Association is used to find relationships between variables in large datasets, often in the form of rules (e.g., market basket analysis). It does not directly group individuals but identifies patterns of co-occurrence.
C . Clustering
Clustering is an unsupervised learning method used to group similar data points based on their features. It is ideal for identifying groups of people with similar tastes without prior knowledge of the group labels. This technique will help the company segment its customer base effectively.
D . Classification
Classification is a supervised learning method used to categorize data points into predefined classes. It requires labeled data for training, which is not the case here as we want to identify groups without predefined labels.
Therefore, the correct answer is C because clustering is the most suitable method for grouping people with similar tastes for targeted product marketing.
NEW QUESTION # 37
A mobile app start-up company is implementing an AI-based chat assistant for e-commerce customers. In the process of planning the testing, the team realizes that the specifications are insufficient.
Which testing approach should be used to test this system?
- A. Static analysis
- B. Exploratory testing
- C. Equivalence partitioning
- D. State transition testing
Answer: B
Explanation:
Whentesting an AI-based chat assistantfor e-commerce customers, thelack of sufficient specifications makes it difficult to use structured test techniques. TheISTQB CT-AI Syllabusrecommendsexploratory testingin such cases:
* Why Exploratory Testing?
* Exploratory testing is usefulwhen specifications are incomplete or unclear.
* AI-based systems, particularly those usingnatural language processing (NLP),may not behave deterministically, making scripted test cases ineffective.
* Thetester interacts dynamicallywith the system, identifying unexpected behaviorsnot documented in the specification.
* Analysis of Answer Choices:
* A (Exploratory testing)#Correct, as it is the best approach when specifications are incomplete.
* B (Static analysis)# Incorrect, as static analysis checks code without execution, which isnot helpfulfor AI chatbots.
* C (Equivalence partitioning)# Incorrect, asthis technique requires well-defined inputs and outputs, which are missing due toinsufficient specifications.
* D (State transition testing)# Incorrect, as state-based testingrequires knowledge of valid and invalid transitions, which is difficult with a chatbot lacking a clear specification.
Thus,Option A is the correct answer, asexploratory testing is the best approach when dealing with insufficient specifications in AI-based systems.
Certified Tester AI Testing Study Guide References:
* ISTQB CT-AI Syllabus v1.0, Section 7.7 (Selecting a Test Approach for an ML System)
* ISTQB CT-AI Syllabus v1.0, Section 9.6 (Experience-Based Testing of AI-Based Systems).
NEW QUESTION # 38
Which ONE of the following statements correctly describes the importance of flexibility for Al systems?
SELECT ONE OPTION
- A. Al systems require changing of operational environments; therefore, flexibility is required.
- B. Al systems are inherently flexible.
- C. Flexible Al systems allow for easier modification of the system as a whole.
- D. Self-learning systems are expected to deal with new situations without explicitly having to program for it.
Answer: C
Explanation:
Flexibility in AI systems is crucial for various reasons, particularly because it allows for easier modification and adaptation of the system as a whole.
* AI systems are inherently flexible (A): This statement is not correct. While some AI systems may be designed to be flexible, they are not inherently flexible by nature. Flexibility depends on the system's design and implementation.
* AI systems require changing operational environments; therefore, flexibility is required (B):
While it's true that AI systems may need to operate in changing environments, this statement does not directly address the importance of flexibility for the modification of the system.
* Flexible AI systems allow for easier modification of the system as a whole (C): This statement correctly describes the importance of flexibility. Being able to modify AI systems easily is critical for their maintenance, adaptation to new requirements, and improvement.
* Self-learning systems are expected to deal with new situations without explicitly having to program for it (D): This statement relates to the adaptability of self-learning systems rather than their overall flexibility for modification.
Hence, the correct answer isC. Flexible AI systems allow for easier modification of the system as a whole.
References:
* ISTQB CT-AI Syllabus Section 2.1 on Flexibility and Adaptability discusses the importance of flexibility in AI systems and how it enables easier modification and adaptability to new situations.
* Sample Exam Questions document, Question #30 highlights the importance of flexibility in AI systems.
NEW QUESTION # 39
A system was developed for screening the X-rays of patients for potential malignancy detection (skin cancer).
A workflow system has been developed to screen multiple cancers by using several individually trained ML models chained together in the workflow.
Testing the pipeline could involve multiple kind of tests (I - III):
I.Pairwise testing of combinations
II.Testing each individual model for accuracy
III.A/B testing of different sequences of models
Which ONE of the following options contains the kinds of tests that would be MOST APPROPRIATE to include in the strategy for optimal detection?
SELECT ONE OPTION
- A. Only III
- B. Only II
- C. I and III
- D. I and II
Answer: D
Explanation:
The question asks which combination of tests would be most appropriate to include in the strategy for optimal detection in a workflow system using multiple ML models.
* Pairwise testing of combinations (I): This method is useful for testing interactions between different components in the workflow to ensure they work well together, identifying potential issues in the integration.
* Testing each individual model for accuracy (II): Ensuring that each model in the workflow performs accurately on its own is crucial before integrating them into a combined workflow.
* A/B testing of different sequences of models (III): This involves comparing different sequences to determine which configuration yields the best results. While useful, it might not be as fundamental as pairwise and individual accuracy testing in the initial stages.
References:
* ISTQB CT-AI Syllabus Section 9.2 on Pairwise Testing and Section 9.3 on Testing ML Models emphasize the importance of testing interactions and individual model accuracy in complex ML workflows.
NEW QUESTION # 40
Consider a machine learning model where the model is attempting to predict if a patient is at risk for stroke.
The model collects information on each patient regarding their blood pressure, red blood cell count, smoking, status, history of heart disease, cholesterol level, and demographics. Then, using a decision tree the model predicts whether or not the associated patient is likely to have a stroke in the near future. One the model is created using a training data set, it is used to predict a stroke in 80 additional patients. The table below shows a confusion matrix on whether or not the model mode a correct or incorrect prediction.
The testers have calculated what they believe to be an appropriate functional performance metric for the model. They calculated a value of 2/3 or 0.6667.
- A. Precision
- B. Recall
- C. Accuracy
- D. F1 -source
Answer: C
Explanation:
The problem describes aclassification modelthat predicts whether a patient is at risk for a stroke. The confusion matrix is provided, and the testers have calculated a performance metric as2/3 or 0.6667.
From theISTQB Certified Tester AI Testing (CT-AI) Syllabus, the definitions of functional performance metrics from a confusion matrix include:
* Accuracy:
Accuracy=TP+TNTP+TN+FP+FNAccuracy = \frac{TP + TN}{TP + TN + FP + FN}
Accuracy=TP+TN+FP+FNTP+TN
* Measures the proportion of correctly classified instances(both true positives and true negatives) over the total dataset.
* If the value is0.6667, it suggests that the metric includesboth correct positive and negative classifications, aligning with accuracy.
* Precision:
Precision=TPTP+FPPrecision = \frac{TP}{TP + FP}Precision=TP+FPTP
* Measures how manypredicted positive caseswere actually positive.
* Doesnotmatch the given calculation.
* Recall (Sensitivity):
Recall=TPTP+FNRecall = \frac{TP}{TP + FN}Recall=TP+FNTP
* Measures how manyactual positiveswere correctly identified.
* Doesnotmatch the 0.6667 value.
* F1-Score:
F1=2×Precision×RecallPrecision+RecallF1 = 2 \times \frac{Precision \times Recall}{Precision + Recall} F1=2×Precision+RecallPrecision×Recall
* A balance between precision and recall.
* The formula isdifferent from the provided calculation.
Since the formula foraccuracymatches the calculated value of0.6667, the best answer isD. Accuracy.
Certified Tester AI Testing Study Guide References:
* ISTQB CT-AI Syllabus v1.0, Section 5.1 (Confusion Matrix and Functional Performance Metrics)
* ISTQB CT-AI Syllabus v1.0, Section 5.4 (Selecting ML Functional Performance Metrics)
NEW QUESTION # 41
Which of the following is correct regarding the layers of a deep neural network?
- A. The output layer is not connected with the other layers to maintain integrity
- B. There must be a minimum of five total layers to be considered deep
- C. There is at least one internal hidden layer
- D. There is only an input and output layer
Answer: C
Explanation:
The syllabus clearly explains the structure of a deep neural network (DNN):
"A deep neural network comprises three types of layers. The input layer receives inputs... Between the input and output layers are hidden layers made up of artificial neurons, which are also known as nodes." (Reference: ISTQB CT-AI Syllabus v1.0, Section 6.1, page 45 of 99)
NEW QUESTION # 42
"AllerEgo" is a product that uses sell-learning to predict the behavior of a pilot under combat situation for a variety of terrains and enemy aircraft formations. Post training the model was exposed to the real- world data and the model was found to be behaving poorly. A lot of data quality tests had been performed on the data to bring it into a shape fit for training and testing.
Which ONE of the following options is least likely to describes the possible reason for the fall in the performance, especially when considering the self-learning nature of the Al system?
SELECT ONE OPTION
- A. There was an algorithmic bias in the Al system.
- B. The unknown nature and insufficient specification of the operating environment might have caused the poor performance.
- C. The fast pace of change did not allow sufficient time for testing.
- D. The difficulty of defining criteria for improvement before the model can be accepted.
Answer: C
Explanation:
* A. The difficulty of defining criteria for improvement before the model can be accepted.
* Defining criteria for improvement is a challenge in the acceptance of AI models, but it is not directly related to the performance drop in real-world scenarios. It relates more to the evaluation and deployment phase rather than affecting the model's real-time performance post-deployment.
* B. The fast pace of change did not allow sufficient time for testing.
* This can significantly affect the model's performance. If the system is self-learning, it needs to adapt quickly, and insufficient testing time can lead to incomplete learning and poor performance.
* C. The unknown nature and insufficient specification of the operating environment might have caused the poor performance.
* This is highly likely to affect performance. Self-learning AI systems require detailed specifications of the operating environment to adapt and learn effectively. If the environment is insufficiently specified, the model may fail to perform accurately in real-world scenarios.
* D. There was an algorithmic bias in the AI system.
* Algorithmic bias can significantly impact the performance of AI systems. If the model has biases, it will not perform well across different scenarios and data distributions.
Given the context of the self-learning nature and the need for real-time adaptability, optionAis least likely to describe the fall in performance because it deals with acceptance criteria rather than real-time performance issues.
NEW QUESTION # 43
The activation value output for a neuron in a neural network is obtained by applying computation to the neuron.
Which ONE of the following options BEST describes the inputs used to compute the activation value?
SELECT ONE OPTION
- A. Individual bias at the neuron level, activation values of neurons in the previous layer, and weights assigned to the connections between the neurons.
- B. Individual bias at the neuron level, and weights assigned to the connections between the neurons.
- C. Individual bias at the neuron level, and activation values of neurons in the previous layer.
- D. Activation values of neurons in the previous layer, and weights assigned to the connections between the neurons.
Answer: A
Explanation:
In a neural network, the activation value of a neuron is determined by a combination of inputs from the previous layer, the weights of the connections, and the bias at the neuron level. Here's a detailed breakdown:
* Inputs for Activation Value:
* Activation Values of Neurons in the Previous Layer:These are the outputs from neurons in the preceding layer that serve as inputs to the current neuron.
* Weights Assigned to the Connections:Each connection between neurons has an associated weight, which determines the strength and direction of the input signal.
* Individual Bias at the Neuron Level:Each neuron has a bias value that adjusts the input sum, allowing the activation function to be shifted.
* Calculation:
* The activation value is computed by summing the weighted inputs from the previous layer and adding the bias.
* Formula: z=#(wi#ai)+bz = \sum (w_i \cdot a_i) + bz=#(wi#ai)+b, where wiw_iwi are the weights, aia_iai are the activation values from the previous layer, and bbb is the bias.
* The activation function (e.g., sigmoid, ReLU) is then applied to this sum to get the final activation value.
* Why Option A is Correct:
* Option A correctly identifies all components involved in computing the activation value: the individual bias, the activation values of the previous layer, and the weights of the connections.
* Eliminating Other Options:
* B. Activation values of neurons in the previous layer, and weights assigned to the connections between the neurons: This option misses the bias, which is crucial.
* C. Individual bias at the neuron level, and weights assigned to the connections between the neurons: This option misses the activation values from the previous layer.
* D. Individual bias at the neuron level, and activation values of neurons in the previous layer: This option misses the weights, which are essential.
References:
* ISTQB CT-AI Syllabus, Section 6.1, Neural Networks, discusses the components and functioning of neurons in a neural network.
* "Neural Network Activation Functions" (ISTQB CT-AI Syllabus, Section 6.1.1).
NEW QUESTION # 44
An airline has created a ML model to project fuel requirements for future flights. The model imports weather data such as wind speeds and temperatures, calculates flight routes based on historical routings from air traffic control, and estimates loads from average passenger and baggage weights. The model performed within an acceptable standard for the airline throughout the summer but as winter set in the load weights became less accurate. After some exploratory data analysis it became apparent that luggage weights were higher in the winter than in summer.
Which of the following statements BEST describes the problem and how it could have been prevented?
- A. The model suffers from drift and therefore the performance standard should be eased until a newmodel with more transparency can be developed.
- B. The model suffers from corruption and therefore should be reloaded into the computer system being used, preferably with a method of version control to prevent further changes.
- C. The model suffers from a lack of transparency and therefore should be regularly tested to ensure that any progressive errors are detected soon enough for the problem to be mitigated.
- D. The model suffers from drift and therefore should be regularly tested to ensure that any occurrences of drift are detected soon enough for the problem to be mitigated.
Answer: D
Explanation:
The problem described in the question is a classic case ofconcept drift. Concept drift occurs when the relationship between input variables and the output variable changes over time, leading to a decline in model accuracy.
In this scenario, theaverage passenger and baggage weightsused in the model changed due to seasonal variations, but the model was not updated accordingly. This resulted in inaccurate predictions for fuel requirements in the winter season. This is an example ofseasonal drift, where model behavior changes periodically due to recurring trends (e.g., higher luggage weights in winter compared to summer).
To prevent such problems:
* Themodel should be regularly testedfor concept drift against agreed ML functional performance criteria.
* Exploratory Data Analysis (EDA)should be performed periodically to detect gradual changes in input distributions.
* Retraining of the modelwith updated training data should be done to maintain accuracy.
* If drift is detected, mitigation techniques such asincremental learning, retraining with new data, or adjusting model parametersshould be employed.
* Option B (Easing the performance standard instead of addressing drift): Lowering the performance standard is not a solution; it only masks the problem without fixing it. Instead, regular testing and retraining should be used to handle drift properly.
* Option C (Corruption and reloading the model): Model corruption is unrelated to this issue.
Corruption refers to accidental or malicious damage to the model or data, whereas this case is due to a changing data environment.
* Option D (Lack of transparency): Transparency refers to how understandable the model's decisions are, but the problem here is a change in data distributions, making drift the primary concern.
* ISTQB CT-AI Syllabus (Section 7.6: Testing for Concept Drift)
* "The operational environment can change over time without the trained model changing correspondingly. This phenomenon is known as concept drift and typically causes the outputs of the model to become increasingly less accurate and less useful."
* "Systems that may be prone to concept drift should be regularly tested against their agreed ML functional performance criteria to ensure that any occurrences of concept drift are detected soon enough for the problem to be mitigated."
* ISTQB CT-AI Syllabus (Section 7.7: Selecting a Test Approach for an ML System)
* "If concept drift is detected, it may be mitigated by retraining the system with up-to-date training data followed by confirmation testing, regression testing, and possibly A/B testing where the updated system must outperform the original system." Why Other Options Are Incorrect:Supporting References from ISTQB Certified Tester AI Testing Study Guide:Conclusion:Since the question describes a situation whereseasonal variations affected input data distributions, the correct answer isA: The model suffers from drift and therefore should be regularly tested to ensure that any occurrences of drift are detected soon enough for the problem to be mitigated.
NEW QUESTION # 45
A word processing company is developing an automatic text correction tool. A machine learning algorithm was used to develop the auto text correction feature. The testers have discovered when they start typing "Isle of Wight" it fills in "Isle of Eight". Several UAT testers have accepted this change without noticing. What type of bias is this?
- A. Complacency/Disregard
- B. Geographical/Locality
- C. Ignorance/Cognitive
- D. Automation/Complacency
Answer: D
Explanation:
Automation bias, also known as complacency bias, occurs when humans over-rely on automated systems and fail to question or validate the system's output. In this scenario, the auto-text correction feature of the word processing tool incorrectly suggests "Isle of Eight" instead of "Isle of Wight." The issue arises because multiple UAT testers accept the incorrect suggestion without noticing it, demonstrating a reliance on the AI- based system rather than their own judgment.
Automation bias is commonly seen in:
* Text correction systems, where users accept incorrect suggestions without verifying them.
* Medical diagnosis AI tools, where doctors may rely too much on AI recommendations.
* Autonomous driving systems, where drivers become overly dependent on automation and fail to react in critical situations.
* Section 7.4 - Testing for Automation Bias in AI-Based Systemsexplains that automation bias occurs when people accept AI-generated outputs without verifying them, often leading to incorrect decisions.
Reference from ISTQB Certified Tester AI Testing Study Guide:
NEW QUESTION # 46
"BioSearch" is creating an Al model used for predicting cancer occurrence via examining X-Ray images. The accuracy of the model in isolation has been found to be good. However, the users of the model started complaining of the poor quality of results, especially inability to detect real cancer cases, when put to practice in the diagnosis lab, leading to stopping of the usage of the model.
A testing expert was called in to find the deficiencies in the test planning which led to the above scenario.
Which ONE of the following options would you expect to MOST likely be the reason to be discovered by the test expert?
SELECT ONE OPTION
- A. A lack of similarity between the training and testing data.
- B. The input data has not been tested for quality prior to use for testing.
- C. A lack of focus on choosing the right functional-performance metrics.
- D. A lack of focus on non-functional requirements testing.
Answer: A
Explanation:
The question asks which deficiency is most likely to be discovered by the test expert given the scenario of poor real-world performance despite good isolated accuracy.
* A lack of similarity between the training and testing data (A): This is a common issue in ML where the model performs well on training data but poorly on real-world data due to a lack of representativeness in the training data. This leads to poor generalization to new, unseen data.
* The input data has not been tested for quality prior to use for testing (B): While data quality is important, this option is less likely to be the primary reason for the described issue compared to the representativeness of training data.
* A lack of focus on choosing the right functional-performance metrics (C): Proper metrics are crucial, but the issue described seems more related to the data mismatch rather than metric selection.
* A lack of focus on non-functional requirements testing (D): Non-functional requirements are important, but the scenario specifically mentions issues with detecting real cancer cases, pointing more towards data issues.
References:
* ISTQB CT-AI Syllabus Section 4.2 on Training, Validation, and Test Datasets emphasizes the importance of using representative datasets to ensure the model generalizes well to real-world data.
* Sample Exam Questions document, Question #40 addresses issues related to data representativeness and model generalization.
NEW QUESTION # 47
Upon testing a model used to detect rotten tomatoes, the following data was observed by the test engineer, based on certain number of tomato images.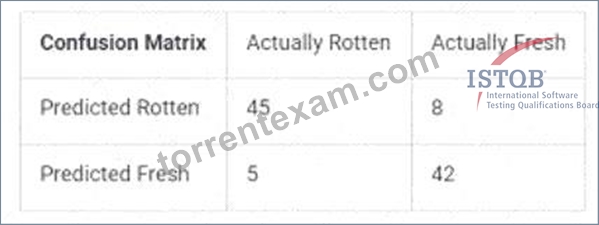
For this confusion matrix which combinations of values of accuracy, recall, and specificity respectively is CORRECT?
SELECT ONE OPTION
- A. 1,0.9, 0.8
- B. 1,0.87,0.84
- C. 0.87.0.9. 0.84
- D. 0.84.1,0.9
Answer: C
Explanation:
To calculate the accuracy, recall, and specificity from the confusion matrix provided, we use the following formulas:
* Confusion Matrix:
* Actually Rotten: 45 (True Positive), 8 (False Positive)
* Actually Fresh: 5 (False Negative), 42 (True Negative)
* Accuracy:
* Accuracy is the proportion of true results (both true positives and true negatives) in the total population.
* Formula: Accuracy=TP+TNTP+TN+FP+FN\text{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN}Accuracy=TP+TN+FP+FNTP+TN
* Calculation: Accuracy=45+4245+42+8+5=87100=0.87\text{Accuracy} = \frac{45 + 42}{45 + 42
+ 8 + 5} = \frac{87}{100} = 0.87Accuracy=45+42+8+545+42=10087=0.87
* Recall (Sensitivity):
* Recall is the proportion of true positive results in the total actual positives.
* Formula: Recall=TPTP+FN\text{Recall} = \frac{TP}{TP + FN}Recall=TP+FNTP
* Calculation: Recall=4545+5=4550=0.9\text{Recall} = \frac{45}{45 + 5} = \frac{45}{50} = 0.9 Recall=45+545=5045=0.9
* Specificity:
* Specificity is the proportion of true negative results in the total actual negatives.
* Formula: Specificity=TNTN+FP\text{Specificity} = \frac{TN}{TN + FP}Specificity=TN+FPTN
* Calculation: Specificity=4242+8=4250=0.84\text{Specificity} = \frac{42}{42 + 8} = \frac{42}
{50} = 0.84Specificity=42+842=5042=0.84
Therefore, the correct combinations of accuracy, recall, and specificity are 0.87, 0.9, and 0.84 respectively.
References:
ISTQB CT-AI Syllabus, Section 5.1, Confusion Matrix, provides detailed formulas and explanations for calculating various metrics including accuracy, recall, and specificity.
"ML Functional Performance Metrics" (ISTQB CT-AI Syllabus, Section 5).
NEW QUESTION # 48
A team of software testers is attempting to create an AI algorithm to assist in software testing. This particular team has gone through over 40 iterations of testing and cannot afford to spend as much time as it takes to run the full regression test suite. They are hoping to have the algorithm reduce the amount of testing required thus reducing the time needed for each testing cycle.
How can an AI-based tool be expected to assist in this reduction?
- A. By using a clustering method to quantify the relationships between test cases and then assigning each test case to a category
- B. By using A/B testing to compare the last update with the newest change and compare metrics between the two
- C. By performing optimization of the data from past iterations to see where the most common defects occurred and select the corresponding test cases
- D. By performing bayesian analysis to estimate the types of human interactions that are expected to be seen in the system and then selecting those test cases
Answer: C
Explanation:
AI-based tools can significantly optimize regression test suites by analyzing historical data, past test results, associated defects, and changes made to the software. These tools prioritize and select the most relevant test cases based on previous defect patterns and frequently failing features, which helps in reducing the test execution time while maintaining effectiveness.
The optimization process involves:
* Prioritizing test cases:AI-based tools rank test cases based on past defect detection trends, ensuring that the most relevant tests are executed first.
* Reducing redundant test cases:The tool can eliminate test cases that do not contribute significantly to defect detection, reducing overall test execution time.
* Augmenting test cases:The AI can also suggest new test cases if certain features are more prone to defects.
This approach has been proven to reduce regression test suite sizes by up to 50% while maintaining fault detection capabilities.
* Section 11.4 - Using AI for the Optimization of Regression Test Suitesstates that AI-based tools can optimize regression test suites by analyzing past test data and defect occurrences, leading to significant reductions in test execution time.
Reference from ISTQB Certified Tester AI Testing Study Guide:
NEW QUESTION # 49
When verifying that an autonomous AI-based system is acting appropriately, which of the following are MOST important to include?
- A. Test cases to verify that the system automatically confirms the correct classification of training data
- B. Test cases to detect the system prompting for unnecessary human intervention
- C. Test cases to detect the system appropriately automating its data input
- D. Test cases to verify that the system automatically suppresses invalid output data
Answer: B
Explanation:
The syllabus highlights that testing for unnecessary human intervention is a key focus for autonomous AI- based systems:
"For autonomous AI-based systems, testers must ensure that the system does not prompt for unnecessary human intervention, as this contradicts the autonomy concept." (Reference: ISTQB CT-AI Syllabus v1.0, Section 8.2, page 59 of 99)
NEW QUESTION # 50
A team of software testers is attempting to create an AI algorithm to assist in software testing. This particular team has gone through over 40 iterations of testing and cannot afford to spend as much time as it takes to run the full regression test suite. They are hoping to have the algorithm reduce the amount of testing required, thus reducing the time needed for each testing cycle.
How can an AI-based tool be expected to assist in this reduction?
- A. By performing Bayesian analysis to estimate the types of human interactions that are expected to be seen in the system and then selecting those test cases
- B. By using a clustering method to quantify the relationships between test cases and then assigning each test case to a category
- C. By using A/B testing to compare the last update with the newest change and compare metrics between the two
- D. By performing optimization of the data from past iterations to see where the most common defects occurred and select the corresponding test cases
Answer: D
Explanation:
The syllabus mentions that AI can help optimize regression test suites:
"An AI-based tool can perform optimization of the regression test suite by analyzing... the information from previous test results, associated defects, and the latest changes that have been made, such as features which are broken more frequently and which tests exercise code impacted by recent changes." (Reference: ISTQB CT-AI Syllabus v1.0, Section 11.4, page 79 of 99)
NEW QUESTION # 51
Which of the following decisions is BEST as a test approach for the described situation?
Choose ONE option (1 out of 4)
- A. You plan experience-based testing by the entire team at the system test level to ensure that the end users are satisfied.
- B. You plan to manually execute regular regression tests of the new camera function, particularly for system tests.
- C. You execute the test cases from the old camera model at the integration test level; no further dynamic tests of the operating data pipeline are necessary.
- D. You plan to perform reviews and exploratory data analysis of the image data sets to reduce the risk of a lack of representativeness of this data.
Answer: A
Explanation:
The ISTQB CT-AI syllabus emphasizes that testing AI-based systems requirescross-functional collaboration andexperience-based testingwhen parts of the team lack domain knowledge. In this scenario, the ML expert understands ML and dataset preparation but lacks knowledge ofcamera system behavior, the device's operational data pipeline, and end-user workflows. The remainder of the team understands the domain and system testing but not ML. Section4.4 - Human Factors and AI Testingand4.3 - System Testing of AI Componentshighlight that when domain understanding is unevenly distributed,experience-based testing conducted by the full team(testers, developers, domain experts) is the most effective approach. This ensures that AI outputs align with actual user expectations and system behavior. OptionCaligns exactly with this principle.
Option A is too limited and does not address the need to validate ML integration. Option B is incorrect because reusing old test cases overlooks AI-specific risks in the operating data pipeline. Option D is useful but focuses only on data representativeness, not system-level user validation. Therefore,Option Cis the best, syllabus-aligned test approach.
NEW QUESTION # 52
When verifying that an autonomous AI-based system is acting appropriately, which of the following are MOST important to include?
- A. Test cases to verify that the system automatically confirms the correct classification of training data
- B. Test cases to detect the system prompting for unnecessary human intervention
- C. Test cases to detect the system appropriately automating its data input
- D. Test cases to verify that the system automatically suppresses invalid output data
Answer: B
Explanation:
When verifyingautonomous AI-based systems, a critical aspect is ensuring that they maintain an appropriate level of autonomy whileonly requesting human intervention when necessary. If an AI system unnecessarily asks for human input, it defeats the purpose of autonomy and can:
* Slow down operations.
* Reduce trust in the system.
* Indicate improper confidence thresholds in decision-making.
This is particularly crucial inautonomous vehicles, AI-driven financial trading, and robotic process automation, where excessive human intervention would hinder performance.
* A. Test cases to verify that the system automatically confirms the correct classification of training data# This is relevant for verifying training consistency but not for autonomy validation.
* B. Test cases to detect the system appropriately automating its data input# While relevant, data automation does not directly address the verification of autonomy.
* D. Test cases to verify that the system automatically suppresses invalid output data# This focuses on output filtering rather than decision-making autonomy.
Why are the other options incorrect?Thus, the mostcritical test casefor verifyingautonomous AI-based systemsis ensuring that itdoes not unnecessarily request human intervention.
* Section 8.2 - Testing Autonomous AI-Based Systemsstates that it is crucial to testwhether the system requests human intervention only when necessaryand does not disrupt autonomy.
Reference from ISTQB Certified Tester AI Testing Study Guide:
NEW QUESTION # 53
......
Best CT-AI Exam Preparation Material with New Dumps Questions: https://dumpscertify.torrentexam.com/CT-AI-exam-latest-torrent.html